
Blog
A Business-Aligned Approach for GCC | Paramount

Getting Data Classification Right: A Practical Approach for GCC Enterprises
Your DLP system flagged 847 “Confidential” documents yesterday. Your business teams marked another 1,200 files the same way by default. Meanwhile, your audit team is asking for evidence of a mature data loss prevention strategy across the NCA and DIFC frameworks.
Sound familiar?
If you’re involved with enterprise data security, you know this reality well. Your organization has invested heavily in DLP tools and classification technology, but the policy coverage remains shallow. Business users either over-classify everything or disengage entirely, leaving you with alert fatigue and little visibility into actual data flows.
The problem isn’t your technology stack. It’s the approach.
Most data classification initiatives fail because they’re designed in IT isolation. There is an utter lack of business context, there’s little to no workflow integration, and there is no sustained ownership needed for regulatory compliance. As a result, you’ll see misused labels, overloaded systems, and security teams chasing meaningless alerts while real risks slip through.
For GCC-based multinationals operating under complex regulatory mandates, this isn’t just inefficient, it’s dangerous. Your audit posture depends on demonstrating measurable maturity in data protection, not just having tools deployed.
What Enterprises Get Wrong About Data Classification
Most classification programs fail not because the enterprise selected the wrong tool, but because the business was never invited to shape the logic behind it.
Enterprises across the GCC continue to invest in DLP, CASB, and cloud security tooling, only to realise months later that data is still leaking, alerts are still noisy, and audits still raise flags.
These are not technical failures. They’re operational design failures.
Here are the common points of failure enterprises typically notice:
1. Classification models are decoupled from the business
Most frameworks are built by security or IT in isolation, based on assumed risk tiers rather than operational priorities. The result: classification categories that mean little to the people actually using them.
- A marketing team doesn’t know whether its campaign data counts as “Confidential” or “Internal.”
- A finance analyst defaults everything to “Restricted” because they don’t want to be blamed for mislabelling.
- Meanwhile, business-critical IP sits under-classified and unprotected, unflagged by automated DLP.
Without a shared understanding, even the best classification logic can collapse into inconsistency.
2. Labels are applied mechanically, not strategically
When classification becomes a routine checkbox, users disengage. That’s when real exposure begins.
If too much is classified as “Confidential,” DLP tools generate a flood of false positives, diluting attention from real risks.
If too little is classified, sensitive data moves freely between cloud apps, email threads, and third-party environments.
In both cases, the cybersecurity strategy looks complete on paper but is ineffective in practice.
3. Governance is weak or missing entirely
Data classification is not just a policy layer; it’s a governance function. Yet in most deployments, no one owns classification oversight.
- There’s no review of misclassifications
- No escalation path for exceptions
- No accountability for recurring misuse across departments
This void creates two outcomes:
1. Business users become cynical, treating classification as compliance theatre.
2. Security teams burn resources chasing low-priority alerts while real breaches go undetected.
4. Implementation is rushed ahead of readiness
Classification labels are rolled out before any user education, workflow alignment, or role-based guidance is in place.
As a result:
- Business leaders resist enforcement, claiming it slows them down
- Teams invent workarounds, often outside sanctioned channels
- Policy audits flag systemic misuse, despite full deployment of data loss prevention strategy tools.
In every case, the damage is reputational, operational, and regulatory. And it’s avoidable if classification is treated not as a control system, but as an organisational function that spans policy, process, and people.
| Failure Type | Impact |
|---|---|
| Over-Classification | DLP fatigue, system bypasses, operational slowdown |
| Under-Classification | Regulatory violations, reputational risk, compromised IP |
| No Governance | No remediation path, inconsistent enforcement, audit flags |
| No Business Alignment | Low adoption, business resistance, policy erosion |
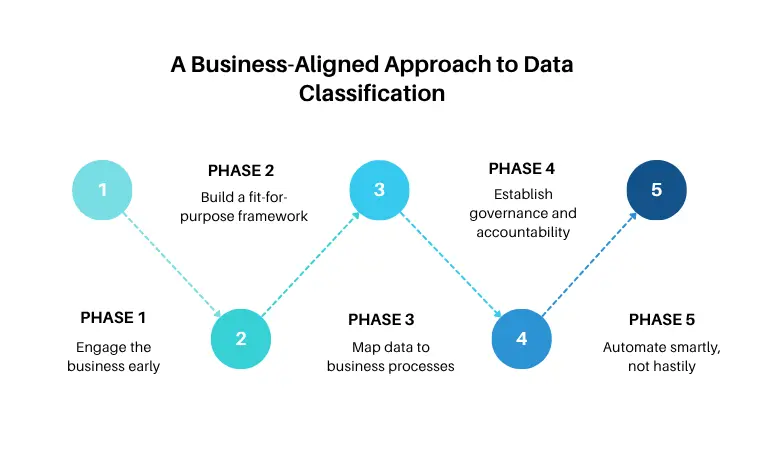
A Business-Aligned Approach to Data Classification
Fixing classification doesn’t start with labels. It starts with context.
When data is classified in isolation, every enforcement mechanism downstream becomes unreliable. DLP alerts become noise. Cloud protections are misaligned. And regulatory audits become defensive exercises.
Here’s how to rebuild classification from the ground up, anchored in the business, not the tooling.
Phase 1: Engage the business early
Most classification models fail because they’re built in IT conference rooms and then enforced on people who were never consulted.
Start with a structured workshop involving risk, IT, legal, and departmental leaders. Your task is to identify:
- What kinds of data are being created and handled daily
- Where that data moves (e.g. between systems, across regions)
- What teams believe is “sensitive,” and why.
These conversations are often the first time the business realises that classification isn’t just about security, it’s about enabling safe, compliant productivity.
Phase 2: Build a fit-for-purpose framework
A classification model should be as simple as it is enforceable. Most enterprises don’t need seven tiers. In GCC markets, a three- or four-tier model often provides the best balance of precision and usability:
- Public – No restrictions, approved for external distribution
- Internal – For internal use only, low sensitivity
- Confidential – Business-sensitive; misuse can impact operations or brand
- Restricted / Regulated – Subject to legal, regulatory, or contractual obligations
Tiers should map directly to enforcement logic in your data loss prevention strategy, access control policies, and cloud computing security services.
Phase 3: Map data to business processes
Classification isn’t about documents. It’s about workflows.
For example:
- An HR document containing salary data may be “Internal” when stored on the intranet, but “Confidential” once sent for external benchmarking.
- Marketing campaign files may be “Internal” pre-launch, and “Public” once cleared for release.
Identify how classification changes across the data lifecycle at rest and in motion. This also helps define what should trigger alerts or block actions.
Phase 4: Establish governance and accountability
You can’t secure what no one owns. Classification requires operational governance:
- Data owners must review and validate classifications
- Security teams must define enforcement rules and reporting protocols
- Business leaders must be accountable for misuse within their teams
This structure prevents misclassifications from becoming systemic and enables course correction before audits or breaches expose the gap.
Phase 5: Automate smartly, not hastily
Once context, logic, and ownership are in place, only then should you apply automation. Integrate automation with:
- DLP and CASB systems
- Cloud platform-native controls (e.g., Azure Information Protection)
- SIEM correlation rules
- Role-based access policies
Automating too early locks in the wrong logic at scale. Doing it at the right point ensures that automation enforces intent, not errors.
How Paramount Enables Sustainable Data Classification Programs
Most classification programs fail because they’re either too vague or too rigid. At Paramount, we help GCC enterprises design and implement business-aligned, scalable frameworks that integrate seamlessly with cybersecurity strategy. We start with cross-functional workshops to uncover risks, co-design relevant classification tiers, and embed them into tools like DLP platforms and endpoint policies.
Our team supports governance activation, policy enforcement, and ongoing maturity—so your program stays resilient under audit, during incidents, and as your business grows.
Key Takeaway
The strongest data loss prevention strategy doesn’t begin with encryption. It begins with knowing what’s worth protecting and ensuring your entire business understands how to handle that data.
Classification is the foundation. But without shared logic, real governance, and consistent usage, it becomes cosmetic. So, if your current framework isn’t producing clarity, confidence, or measurable control, it’s time to revisit the model.
If your DLP strategy isn’t reducing risk, it’s time for a rethink. Let’s design a classification approach that’s built to last. Talk to us.
Recent Posts
- Navigating the Landscape of Data Privacy Protection across the GCC
- History of DNS Abuse Attack Vector & Countermeasure
- Never Trust, Always Verify: Why Zero Trust is the Key to Modern Cyber Defense
- Everything You Need to Know About IGA Light
- How to Choose the Right Cybersecurity Solution for Your Business in Middle East

Protect your online assets from cyber threats with Paramount
Comprehensive cyber security solutions for individuals and businesses
Significantly reduce the risk of cyber threats and ensure a safer digital environment.